A blockchain is a chain of blocks, where a block is a blob of data holding relevant transactions and other data. This means that Octez — the Tezos blockchain implementation to which Nomadic Labs contributes — should optimize how it handles this particular data structure.
The recently-released Version 10 of Octez introduces a new storage backend for Octez, with new features and performance improvements (referenced as v0.0.6 in the Changelog).
In this blog post we will outline what these optimizations are, and how they work.
Octez node’s store in a nutshell
The storage layer of an Octez node has two parts:
- the context, containing the ledger state as a git-like versioned repository, and
- the store, containing the blocks, operations and protocols of the chain.
Our Version 10 update is to the store part; context storage is unchanged.
The previous implementation relied on the generic key-value database LMDB. This works, but because it is generic it cannot accomodate optimizations that (in the Tezos use-case) would increase performance.
Therefore, we implemented a bespoke storage layer to optimize read/write speed, memory usage, storage size, and concurrent access.
The key insight
LMDB introduces a global lock when writing new data to the store. It has to because (in the general case) it cannot know how a write might affect the database.
Global locks are expensive, and in the Tezos use-case they are mostly unnecessary: intuitively, blockchains consist mostly of immutable data — except for forks on recent blocks as discussed below — so we know that fresh writes will not affect data if it is old enough, and in fact only a small lock on some concurrent read accesses is required.
We need a little background before we can flesh out the particulars of how to turn this insight into an optimized implementation:
Some background on time and consensus
- In Tezos, time is split into cycles, where currently 1 cycle = 8192 blocks ≈ 68 hours.1
- Tezos reaches global consensus about the state of the chain in a few levels, under normal network conditions.2 To have a very generous safety margin, Tezos considers that there cannot exist a fork that is longer than 5 cycles ≈ 14 days.
Thus the blockchain can be treated conceptually as consisting of
- a long chain of immutable (cemented) blocks which come before the no fork point, and for which consensus is certain, and
- a recent and shorter chain of possibly mutable blocks which come strictly after the no fork point, for which consensus (finality) is uncertain.
We illustrate this with a graphic:
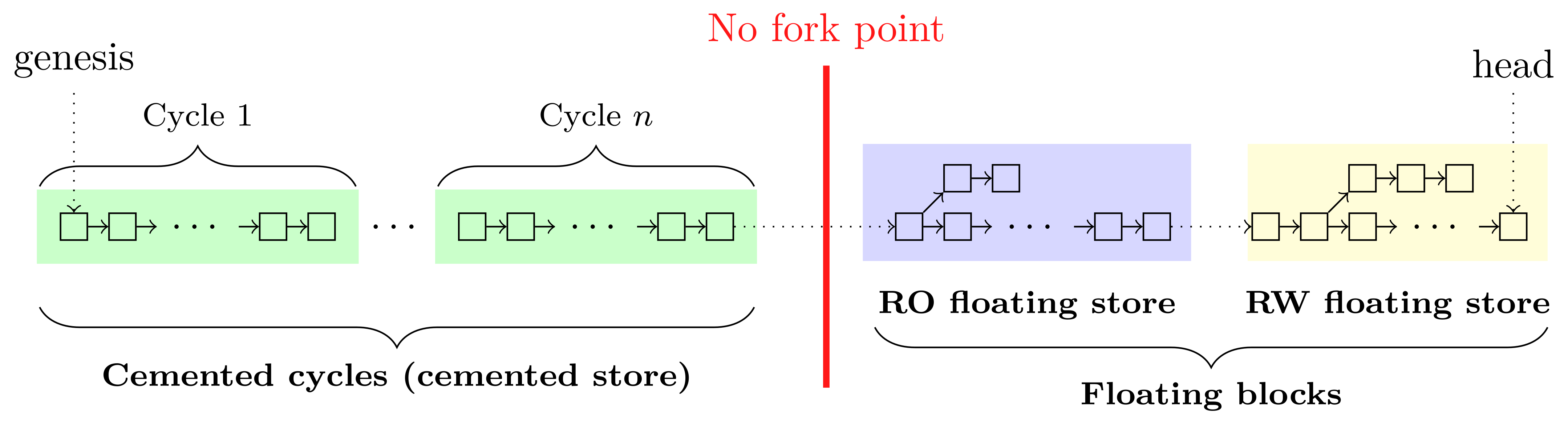
This new structure allows us to optimize the store, as we discuss next.
The new store structure
Cemented store
Cemented store manages cemented cycles (left of the no fork point illustrated above), which contain cemented blocks. A cemented cycle is a contiguous list of blocks which reflects the same notion of cycles from the economic protocol. These are immutable so they can have a fast ‘cemented look-up’:
- We assume finality for cemented blocks, so history is canonical in the sense that every node has the same cemented storage representation.
- The block metadata of each cemented block can be compressed, to reduce storage size.3
- We maintain two indexes that allow for rapid block accesses, increasing the overall process performance: a
hash -> levelindex, and its converselevel -> hash. These are cheap to implement and maintain, because we know they need not be updated once they have been populated.
Floating store
The floating store splits blocks further into two sub-stores:
- a Read Only (RO) floating store of blocks, and
- a Read Write (RW) floating store.
The RO store is read-only; no blocks are added, removed, or updated. The RW store is append-only; no blocks are removed or updated, but blocks may be added.
A quick summary of why we have this distinction:
-
The RO store contains any blocks left over from the floating store of the previous merge procedure that were neither cemented nor trimmed. Details are below.
-
The RW store contains any blocks that have arrived since the previous merge procedure was initiated.
-
The floating store (RO+RW) contains blocks which are candidates for reorganization or trimming. It may contain forks and consensus is not final.
We now come to the merge procedure, whereby blocks in RO+RW are examined, organized, trimmed, and (where appropriate) shifted from the floating to the cemented store:
The merge procedure
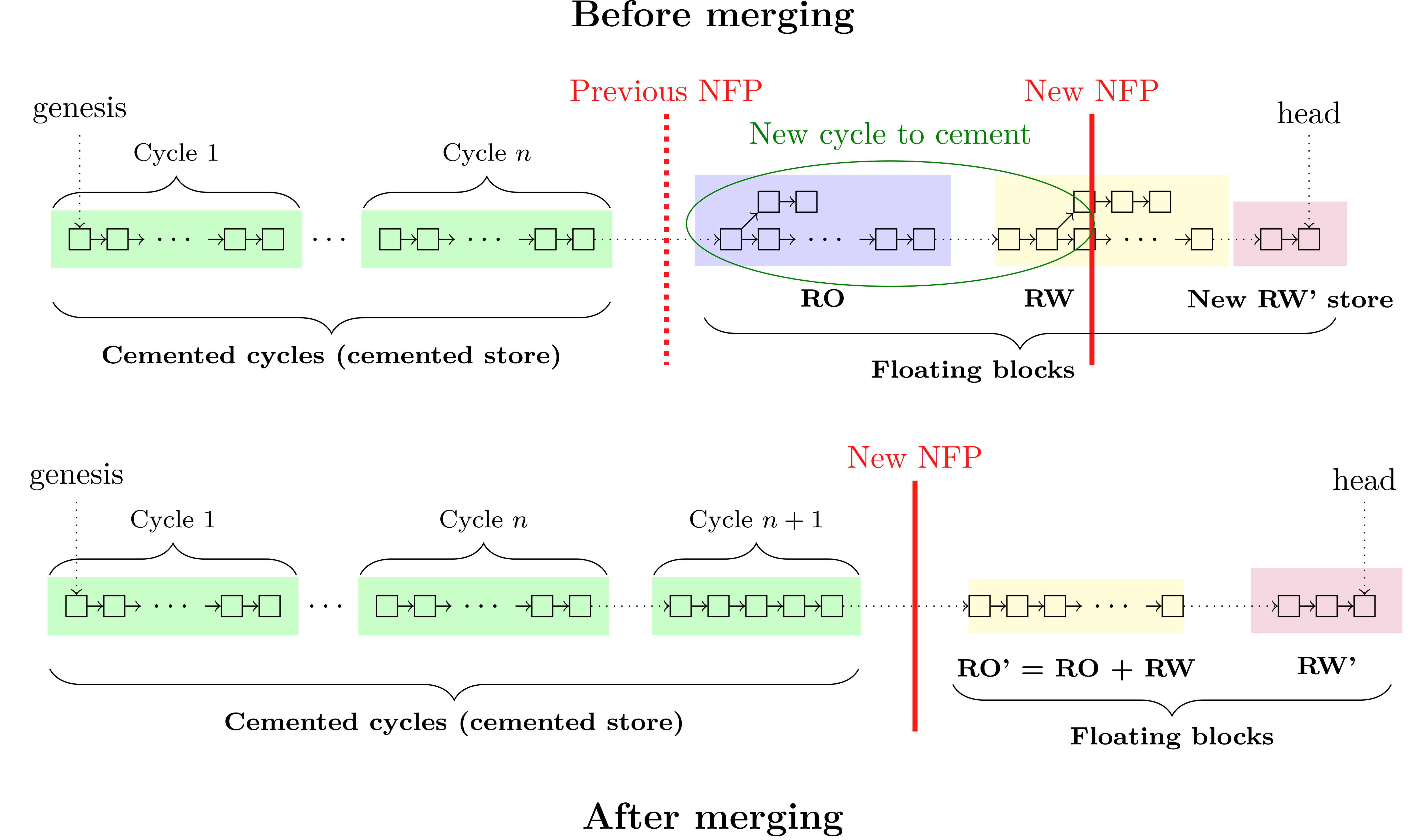
When shifting the no fork point forward,4 we move some blocks from the floating store to the cemented store using a merge procedure, as follows:
- Initiate the merge procedure by locking RW so no further appends are accepted. To ensure liveness during and after the the merge procedure, create an empty RW’ store to store blocks as they continue to arrive.
- Retrieve the blocks between the previous no fork point (Previous NFP) and the new no fork point (New NFP), starting from the head. This corresponds to the cycle(s) that we might cement.
- Trim branches in the selected cycle(s) to those that remain valid according to the consensus algorithm.
- Cement the blocks for which we have consensus and place them in a new cemented cycle.
- Combine any leftover blocks — meaning blocks in RO+RW that were not deleted by the trimming procedure, but for which consensus is uncertain so that they have not made it into the cemented store — into a new RO’ store.
- Promote the RO’ and RW’ as the new RO and RW stores.
Performance benchmarks
These benchmarks were computed on a mid-range laptop with SSD storage running a Tezos node with Mainnet data (which at time of benchmarking had approximately 1.65 million blocks).
Store overall performance
With the bespoke store format discussed above, our new storage backend significantly reduces the node’s disk I/O requirements, memory consumption, and storage footprint.
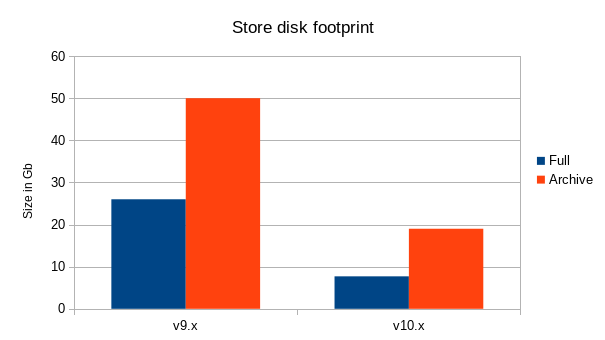
We can benchmark the storage footprint below as follows:
- The block history maintained by a Mainnet node in full mode now requires around
8GBof disk space, compared to more than26GBbefore. - The block history required in archive mode now requires
20GBof disk space, compared to between40GBand60GB.
Snapshot overall performance
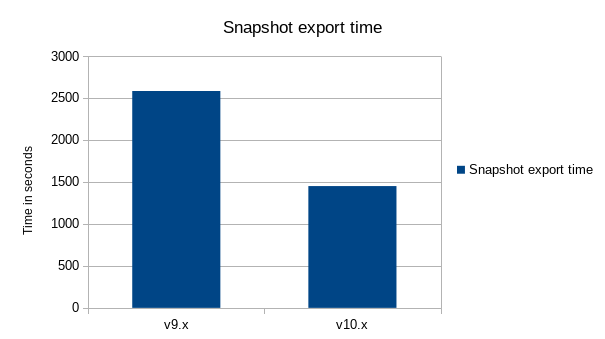
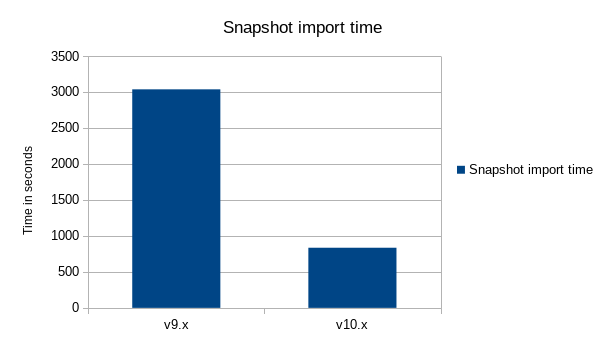
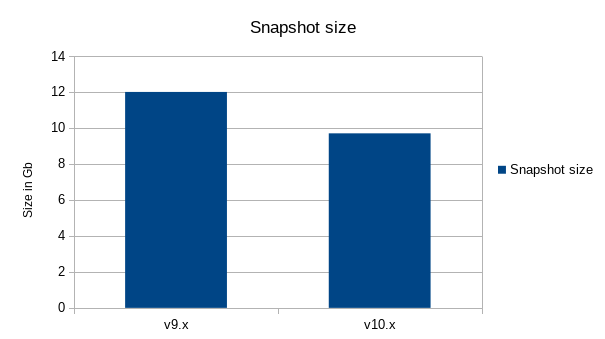
Thanks to the new snapshot version and new store format — moving from the v.0.0.1 (in Octez <= 9.x) to v.0.0.2 (in Octez >=v10.x) — snapshots are lighter and faster to import and export.
Indeed, snapshots are now based on the canonical layer of the store, which allows more optimizations:
- Snapshot export time is improved by 1.8x, and snapshot import time is improved by 3.7x.
- Snapshot size, for full mode, is reduced by around 20%.
New features of the storage backend
The new storage backend of Octez version 10 is lighter and faster as discussed above. It is also more resilient and contains numerous other improvements and tweaks. We conclude with a brief changelog:
- New snapshot format (
v2) is lighter and faster to export and import and can be exported in two formats:- (default) as a
tararchive: easy to exchange, - as a
rawdirectory: suitable for IPFS exchange thanks to the canonical representation of the block history.
- (default) as a
- A new command
tezos-node snapshot infoallows to inspect the information of a given snapshot. - Rolling mode is now labelled as
rolling mode, rather thanexperimental-rolling. - Reworked history modes to be able to configure a cycle offset to preserve more cycles, if needed. By default, the node now retains 5 cycles with metadata below the no fork point (i.e.
full+5), instead of 3 cycles (i.e.full+3). - The store is more resilient thanks to a consistency check and an automatic restore procedure to recover from a corrupted state, meaning that if (for example) power to your node cuts, you are more likely to be able to just reboot and carry on.
Further details of new features, and information on how to upgrade, are in the full Octez v10 changelog.
-
At time of writing Tezos is running the Granada protocol, in which a block lasts 30s during typical, normal operation. Thus, 1 block = 30s and 1 cycle = just over 68 hours. Since this blog post is written from the point of view of Tezos, we will take blocks and cycles as our primitive notion of time henceforth (rather than seconds and hours). You know you think about blockchain too much, when you tell your child “hurry up to bed, it’s just 20 blocks till bedtime”. ↩
-
A discussion of Nakamoto-style consensus is here (based on Emmy*) and one of classical BFT-style consensus is here (based on Tenderbake). For the purposes of this blog post, all that matters is that there are blocks, and consensus is reached. ↩
-
Compressing data reduces storage size but introduces overhead since accessing the data requires some computation to decompress it. However, the cemented blocks are infrequently accessed so for cemented store, this tradeoff is worthwhile. ↩
-
When the no fork point moves, and how far, is governed by constants and algorithms in the current economic protocol. In practice the economic protocols so far just choose constants such that the fork point gets updated to remain relatively recent, yet far enough into the past for consensus to be certain. ↩