As we have discussed earlier on this blog, notably in
the post on regression testing,
testing is an important complement to formal
verification. A critical task when testing is to ensure a high degree
on test coverage. In this post we discuss how we measure test coverage
of the OCaml implementation of tezos using bisect_ppx,
and our work towards ensuring that the Michelson interpreter of the
node is fully covered by tests.
Test coverage
Testing is simpler to set up than formal verification but comes with a major caveat: it is incomplete. Each test run verifies only one execution path — as opposed to formal methods that can give guarantees on all possible execution paths of the system under test.
The incompleteness of testing provokes a natural question in the mind of the wary test engineer: to what extent do my tests cover the set of behaviors of the tested system? Or, what parts of the code are tested and what parts are not? Many measures have been proposed to answer these and related questions, collected under the term of “test coverage”.
In this blog post, we focus on one such measure, namely program point coverage. This consists of measuring the ratio of program points (informally, a program point can be thought of as a location in the source code) that have been visited during the test run. Other measures include function coverage (which functions have been visited?), edge coverage (which edges in the program’s control-flow graph have been visited?) and condition coverage (which boolean sub-expressions in guard-expressions have been evaluated to both true and false).
However, full coverage does not imply that all behaviors of the system has been explored, not for any of the measures above. Notably, the behavior of a program statement may change depending on the program state when the statement is executed. But none of the above measures quantify to what extent possible such program states are explored. Instead, they are defined in terms of control-flow graph properties of the tested executions. The takeaway is that full code coverage does not guarantee full system correctness.
Nonetheless, there is still value in pursuing a high degree of test coverage. First, it is an important proxy measure for the amount of testing that has been performed. And second, because it detects code that has not been tested at all. Such code may contain bugs that are triggered when executed in any program state. Systematically testing code is a cheap insurance against such bugs.
In this section, we will detail our usage of the
bisect_ppx tool to measure
program point coverage in the Michelson interpreter by our test suite.
The bisect_ppx code coverage tool
bisect_ppx is a code coverage tool for OCaml and Reason programs.
A program that has been compiled with bisect_ppx
writes a log file with coverage data just before terminating.
A set of such log files can be converted into an HTML report
detailing and summarizing the set of program points that has been
visited during the execution.
For each instrumented .ml file that has been visited we obtain a
coverage measure (e.g. “73% of the program points were visited”), and
each file can be inspected in detail to understand what program points
have been visited and not.

bisect_ppx instruments the tested program by inserting code that
associates each program point with a counter that is incremented when
the program point is visited. Then, when compiled, the instrumented
program is linked with bisect_ppx‘s run-time library. This library
registers an
__atexit
hook that is called at the end of the instrumented program’s execution.
This hook writes the program-point counters to a log file. At this
point, the developer can run their test suite to gather coverage data.
Finally, the bisect-reporter-ppx program included in
bisect_ppx, reads the log files and generates an HTML report.
An example of bisect_ppx instrumentation
Consider the following test file for which we want to measure coverage:
let add n1 n2 = n1 + n2
After running bisect_ppx we obtain the following, instrumented
source code:
module Bisect_visit___src___lib_addition___addition_lib___ml =
struct
let ___bisect_visit___ =
let point_definitions =
"\132\149\166\190\000\000\000\004\000\000\000\002\000\000\000\005\000\000\000\005\144\160P@" in
let `Staged cb =
Bisect.Runtime.register_file "src/lib_addition/addition_lib.ml"
~point_count:1 ~point_definitions in
cb
end
open Bisect_visit___src___lib_addition___addition_lib___ml
let add n1 n2 = ___bisect_visit___ 0; n1 + n2
We see that bisect_ppx has added a module
Bisect_visit___src___lib_addition___addition_lib___ml containing
a serialized definition of the program points in the source file, and
a function ___bisect_visit___ that increments a program point
counter. The function add has been associated to program point 0.
Hence, the ___bisect_visit___ function is called in the definition
of add with the argument 0. Consequently, each call to add
increments the counter for program point 0.
Test coverage for the Michelson interpreter
We have used bisect_ppx to measure the test coverage of the
Michelson interpreter in the Tezos node, and to detect Michelson instructions that were
lacking test cases. We had two goals: first, to make sure that each
branch of the step function in the interpreter (corresponding roughly to each
Michelson instruction) is covered by at least one test. Second, to
make sure that each instruction has at least one dedicated test. Our
work on this topic can be followed in merge request
!1261, that also
contains information on how to set up bisect_ppx for Tezos.
To measure progress on the first objective, we run bisect_ppx on the
full test suite of the Tezos node. For the second objective, we run it
using a test suite that targets individual Michelson instructions.
Baseline results
We take as our baseline commit #0478afc7 of the Tezos node. This
version precedes our work towards full coverage, and for this reason has a low coverage.
The results using bisect_ppx for the Michelson instruction
test suite are available here.
We see that the test suit for instructions covers 60.79% of the interpreter.
Several instructions are missing tests: instructions for big maps such as
EMPTY_BIG_MAP,
MEM and
GET; the instructions SOURCE and SENDER related to the transaction in which a contract is executed; and arithmetic operations such as INT that converts an integer (int) to a natural number (nat).
The coverage obtained when using the full Tezos node test suite
is better, at 70.21% test coverage. However, it is still
worrying to see that some instructions, such as SIZE for lists and
MAP for maps, have no tests at all!
Adding Tests
There is a simple solution to the lacking coverage: writing more
tests. Fortunately, this is often quite straightforward using the
Python Execution and Testing Framework for
Tezos. This framework provides a programmable API for the tezos-client and tezos-node binaries.
Writing tests is especially simple for instructions such as INT,
that depend only on the state of the stack.
We will have to do some more work for instructions such as SOURCE that
interact with the block chain.
Testing simple instructions
For simple instructions, our testing approach consists of
writing a simple contract that takes a sample input of the instruction by
parameter, and leaves the result of the instruction in storage. For
instance, to test the INT operation, we write the contract int.tz:
parameter nat;
storage (option int);
# this contract takes a natural number as parameter, converts it to an
# integer and stores it.
code { CAR; INT; SOME; NIL operation; PAIR };
Then, we write a pytest that executes the contract
with a sample input, retrieves the
resulting storage and asserts that it is equal to the expected one.
As we have a large number of tests like this, we use
pytest parameterization.
This enables the execution of the same test with different parameters.
In our case,
we write one test method that is parameterized by a
tuple (contract, param, storage, expected).
def test_contract_input_output(self, client, contract, param, storage, expected):
contract = f'{CONTRACT_PATH}/{contract}'
run_script_res = client.run_script(contract, param, storage)
assert run_script_res.storage == expected
It runs contract, using the run script command of
tezos-client. Here, client is a fixture provided by the Tezos
Python Execution and Testing framework, that wraps a tezos-client
binary. The run script command is called with the parameter param
and the initial storage storage. Then, the test verifies that after
execution, the final storage contains expected.
For instance, to test the INT instruction, we could instantiate the
test parameters with ('int.tz', 'None', '0', '(Some 0)'), meaning that
the when the int.tz contract is passed 0 by parameter, then the
final storage should contain (Some 0).
These instantiations are given by decorating the test method.
The resulting code looks like this:
@pytest.mark.parameterize(..., [
# ...
# Test INT
('int.tz', 'None', '0', '(Some 0)'),
('int.tz', 'None', '1', '(Some 1)'),
('int.tz', 'None', '9999', '(Some 9999)'),
# ...
])
def test_contract_input_output(self, client, contract, param, storage, expected):
# ...
More involved testing
Testing instructions that depend on the state of the block chain
requires more effort, as exemplified by our tests for the SOURCE instruction.
This instruction pushes the address of the contract that initiated the
current transaction, called the source. Note that this may differ from the sender,
which is the address of
the contract that initiated the current internal transaction and
that is obtained by the SENDER instruction.
Let us demonstrate the difference between the two instructions with a
scenario involving two contracts. The first
contract, receiver, puts the result of SOURCE in storage:
parameter unit;
storage address;
code { DROP; SOURCE; NIL operation; PAIR }
The second contract, proxy, transfers whatever amount
it receives to another contract, as specified by the parameter
of the transaction:
parameter (contract unit);
storage unit;
code {
UNPAIR;
AMOUNT;
UNIT;
TRANSFER_TOKENS;
DIP { NIL operation };
CONS;
PAIR
}
Now, assume that the contract bootstrap2 creates a transaction to the proxy contract
sending 99 ꜩ and giving the address of the receiver contract as parameter . Then
the smart contract proxy creates an internal transaction that transfers the received 99 ꜩ to
receiver. This is illustrated by the following figure:
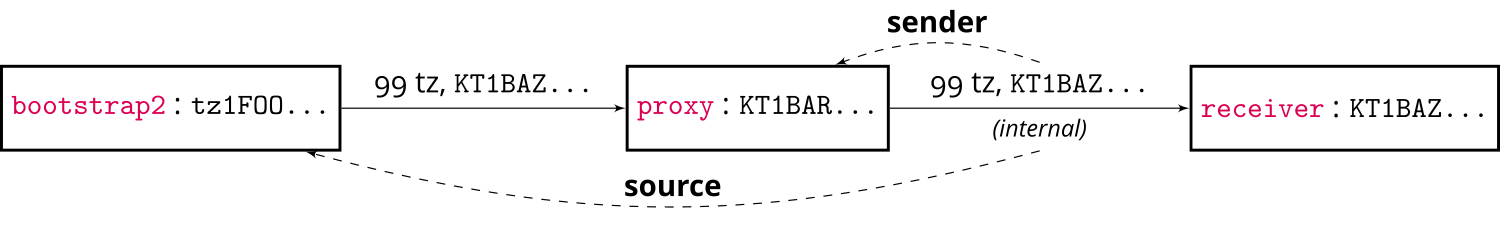
In this scenario, the source of the internal transaction (from
proxy to receiver) is bootstrap2, whereas the sender of that
transaction is the proxy.
We test SOURCE to verify that it operates as expected.
First, we test a direct transfer from bootstrap2 to the receiver
contract, and then a transfer through the proxy
contract as in scenario described above. In both cases, we assert that
source address left in storage of receiver is that of bootstrap2:
def test_source(self, client):
init_store = IDENTITIES['bootstrap4']['identity']
init_with_transfer(client,
f'{CONTRACT_PATH}/receiver.tz',
f'"{init_store}"',
1000, 'bootstrap1')
# direct transfer to the contract
client.transfer(99, 'bootstrap2', 'receiver', ['--burn-cap', '10'])
bake(client)
source_addr = IDENTITIES['bootstrap2']['identity']
assert_storage_contains(client, 'receiver', f'"{source_addr}"')
# indirect transfer to the contract through proxy
contract_addr = client.get_contract_address('receiver')
client.transfer(99, 'bootstrap2', 'proxy',
['--burn-cap', '10', '--arg', f'"{contract_addr}"'])
bake(client)
assert_storage_contains(client, 'receiver', f'"{source_addr}"')
Final results
From the beginning, we’ve had a reasonable degree of testing in place;
which was reflected in the core’s stability. Despite this, we committed
to achieving 100% (or close to it) of code coverage. To that end, since
April 2019, we have added 7191 new Python integration tests, using 66 new test
contracts. As a result of this effort, we now obtain a
code coverage of 99.12%2
for the tests for the instruction integration tests and 100% for the full contract test
suite. We cover all branches of the interpreter function in
script_interpreter.ml.
In addition to quantifying the confidence in the test suite of the
interpreter, bisect_ppx helped us discover dead code in the
interpreter. The interpreter contained a “peephole optimization” for
the UNPAIR macro.
This optimization was supposed to match the expansion of the UNPAIR
macro and transform directly a stack on the form (Pair a b) : S to
a stack of form a : b : S, without executing the full expansion.
To our surprise, we discovered that this
branch of the interpreter is never visited during testing. Quite
unexpectedly, since the UNPAIR macro is very commonly used in our test contracts.
It turns out that the optimization of UNPAIR was never applied. The
expansion of this macro had been changed since the optimization was
added to the interpreter, but the optimization had not been updated to
match. Consequently, the pattern match in interpreter no longer
matched the actual definition of UNPAIR. Thanks to bisect_ppx, we
were able to detect this dead code. As gas updates in
Babylon
removes much of the gains from this optimization, we removed it in
the current Carthage
protocol.
Conclusion
Now that we have achieved a high level of code coverage in the interpreter, the next goal is to maintain this level and to extend it to remaining parts of the Tezos code base.
For the first objective, we have added code coverage measurements to our continuous integration system. This lets developers calculate test coverage through a button push in the CI’s interface. In the future, we would also like a developer to be automatically informed if, for example, they add a new Michelson instruction but forget to add tests verifying its implementation.
For the second objective, we are working on covering fully the type checker of Michelson, currently at 75.94% percent. To achieve this goal, we are writing both unit tests and integration tests. We are also encouraging developers to add automatic tests for all new functionality and when modifying existing behaviors.
End Notes
-
For Python test cases, this counts the difference between test items collected by pytest when running
pytest tests_python/tests/test_contract*in commit#0478afc7and in commit#395bee9dc. For test contracts, this counts the difference between the number of*.tzfiles present in thesrc/bin_client/test/respectivelytests_python/contractsin commit#0478afc7respectively commit#395bee9dc. ↩ -
The missing 0.88% percent comes from a case of the deprecated
STEPS_TO_QUOTAinstruction which is unreachable through thetezos-clientcommands used for integration testing of contracts. ↩