Changes in Michelson
As hinted at in a previous blog post, we’ve been working on improving different parts of the protocol, including our favourite smart contract language: Michelson.
The changes made to Michelson in this proposal intend to simplify smart contract development by making the code of complex contracts simpler and cleaner. In particular:
- smart contracts now support entrypoints
- contracts can now create, store and transmit as many big_maps as they want
- comparable types are now closed under products (i.e. the pair constructor)
- a new instruction,
CHAIN_ID, allows contracts to differentiate between the test chain and the main network - a gas cost overhaul has been integrated, and
STEPS_TO_QUOTAhas been disabled until a more robust semantics is found.
Some new instructions have been added in order to make Michelson a better compilation target for high level languages:
- new stack instructions
DIG n,DUG n,DIP n { code },DROP n - support for partial application and closures with the
APPLYinstruction
Finally, a series of changes implement the new, cleaner, distinction between accounts and smart contracts as described in Cryptium Labs’ blog:
- the instruction
CREATE_ACCOUNTdisappears - the type of
CREATE_CONTRACTchanges, as a consequence of the amendments described in Cryptium Labs’ blog - during the migration, the manager operations currently implemented at the protocol level will be automatically converted into smart contract entrypoints.
We’re going to go through these in more details, but before we continue, you should know that some of these will introduce BREAKING CHANGES for application developers. The changes should NOT break or radically change the semantics of existing contracts. It may ONLY change the interface that they expose. As a consequence, shallow changes to the rest of your stack may be needed.
In particular:
- some RPCs will expect different inputs and provide different outputs;
- the binary representation of operations will change due to both the account rehaul and entrypoints;
- the introduction of multiple entrypoints can
give a special meaning to some existing annotations on arguments (such as
%default), changing the type of some pre-existing contracts; - some gas costs are updated.
If you maintain a tool relying on RPCs or binary formats, or are a contract writer, please test your tools. We tried to keep the changes as local and manageable as possible.
More details are provided throughout this article and we will make forthcoming communications to aid this transition.
Multiple entrypoints
Lightweight multiple entrypoints are one of the most important new features of this proposal, as they let you define extensible standard interfaces for smart contracts. Concretely, entrypoints leverage the annotation mechanism to call specific parts of the target smart contract code in an easy way.
Usage
Entrypoints correspond to annotations in the input type of a Michelson
contract, such as parameter (or (int %set_age) (string %set_name)).
Calling a contract at entrypoint %set_age with argument 12 is easy:
tezos-client transfer <AMOUNT> from <CALLER> to <CONTRACT> --entrypoint set_age --arg 12
Overview of entrypoints
Entrypoints allow a contract to be seen as a collection of independent functions sharing a storage, and thus to call explicitly one of these functions.
We call them lightweight because we’ve taken care of making very few
changes to the language to preserve the semantics of existing
contracts: an entrypoint is simply an annotation, in the parameter
type of the contract, on the branch of interest in a tree of or types.
A consequence of this choice is that it is already possible today to deploy a contract in Athens that would take advantage of entrypoints if and when they get deployed.
When calling a contract’s entrypoint, instead of specifying the
succession of Left/Right constructors leading to the expected case,
we only need to explicitly specify the name of the entrypoint.
It brings more than just a convenience to avoid writing Lefts and
Rights, as it allows one to call the entrypoint without any knowledge of
the contract’s full type — i.e. the type of all other entrypoints —
whereas today’s Michelson semantics forces any caller of a contract to
know it. Thus we gain flexibility in the interactions with and
especially between contracts.
Current Michelson semantics
In all pasts and current protocols (including Athens), there is no
explicit entrypoint. The usual solution to this problem is to encode
entrypoints thanks to the type disjunction or. As an example, consider
the parameter type of a contract having multiple functionalities: spending the
token of the contract, setting its delegate, doing some business requiring a string as input, and
getting a callback answer carrying a string and a nat.
parameter
(or
(or %manage
(or
(pair %spend mutez key_hash)
(key_hash %set_delegate))
(unit %default))
(or
(string %contract_business)
(pair %contract_callback (string %id) (nat %value))));
Any contract wanting to perform a call to e.g. the last entrypoint needs
to wrap its parameter (of type (pair string nat)) in a sequence of two Rights.
This is not satisfactory for at least two reasons:
- the position of the entrypoint of the target contract leaks into the code of the caller, which is just plain ugly
- another target contract with a similarly typed entrypoint but at a different position would require a different wrapping in the caller
Clearly, this solution doesn’t scale and is not composable.
To bypass these issues, one would have to rely on coincidental
polymorphism offered by PACK/UNPACK, or to originate proxy contracts
satisfying other contract’s expectations while carrying
information in their storage to proceed as intermediaries between our
contract and third-party contracts. Not very satisfactory either.
Naming entrypoints of a contract and calling an entrypoint
Having multiple named entrypoints brings more polymorphism, hiding
irrelevant parts of the parameter type to callers: the third-party
can use the entrypoint name to call our contract and it just needs
to know the type of the data expected by this entrypoint - neither
the path that leads to this entrypoint, nor the type of
other branches have to be known. In our previous example, using the
new functionality, a third party contract can send data to our
entrypoint using CONTRACT %contract_callback (pair string nat).
Here are the rules to define entrypoints. First of all, entrypoints
need to be named in the contract’s parameter type. To do so, the parameter
has to be a tree of or types (with possibly other types at the leaves).
Any annotation of a type constructor in this nesting of or types accessible
through Left/Right will become an entrypoint.
So, in the example above %manage, %spend, %set_delegate,
%contract_business, %contract_callback are entrypoints, while %id
and %value are not. Note that it is possible for entrypoints
to be nested: %spend and %set_delegate are under the %manage point.
The only constraints are, first, that a contract cannot define two entrypoints
with the same name and, second, that, should there be an entrypoint named %default
then all branches of the disjunctive type must be annotated with some
entrypoint. Otherwise, we could have reachability problems: consider
the (wrong) parameter type:
(or (or %default (mutez %amount) (nat %counter) string))
It is impossible to access the branch of type string: calling
the contract without entrypoint will select %default.
“What will happen to my old contract?”
The overwhelming majority of contracts with scripts will stay completely untouched. A few contracts originated before this amendment may undergo automated transformations to render them compatible with the new protocol. All these transformations are done in a way which minimizes breakage and mostly preserves the semantics. See below for more information.
More flexible big maps
Relaxing the constraints on big maps is the other big quality-of-life improvement we bring to Michelson. Big maps are used for storing anything that does not need to be loaded upfront when calling a smart contract. Having only one big map led to unhealthy development patterns. This proposal fixes that issue.
Overview
Currently (in Athens), each contract can have at most one big map
in its storage. Our proposal lifts this restriction and allows contracts
to store and manipulate an arbitrary amount of big maps in their storage.
What’s more, contracts calls can take big maps as arguments! The instruction
EMPTY_BIG_MAP k v is introduced to push an empty big map with keys
of type k and values of type v on the stack.
Not all restrictions are lifted, though: big maps cannot be shared among contracts, i.e. a big map can appear in the storage of at most one contract. Moreover:
- big map types cannot be nested or appear as arguments of
PUSHandUNPACKinstructions - when duplicating a big map, the full storage cost for duplication is charged (no sharing)
Under the hood
The machinery for handling big maps got slightly more complicated in order to preserve the invariants mentioned above. Now, big maps are not stored along contracts but rather in a dedicated area of the protocol state. Contracts manipulate big maps by their internal ids, which are internally represented as integers. More details will be provided with the full changelog for this proposal.
New instructions
Stack manipulation instructions
The new stack manipulation instructions aim at making compilation from
higher-level languages easier, but they should also be very useful for
those savvy users that write directly in Michelson. Currently, the stack
is manipulated “one element at a time”: in order to access an element
deep down in the stack, one has to perform a complex sequence of
reshuffling instructions. The new instructions capture these typical
use cases. In what follows, we will denote by 'a{n} families of
type variables indexed by the naturals. The behaviours of these instructions
is pretty straightforward and is easily deductible from their types.
- The
DIG ninstruction takes the element at depthnof the stack and moves it on top. The element on top of the stack is at depth0so thatDIG 0is a no-op. The type ofDIG nis the following:
DIG n :: 'a{1} : ... : 'a{n} : 'b : 'C -> 'b : 'a{1} : ... : 'a{n} : 'C
DUG ndoes the opposite ofDIG n. It places the element on top of the stack at depthn. It follows thatDUG 0is also a no-op. Here is its type:
DUG n :: 'b : 'a{1} : ... : 'a{n} : 'C -> 'a{1} : ... : 'a{n} : 'b : 'C
- The new
DIP n { code }generalizesDIP { code }and allows to executecodeprotecting thenfirst elements of the stack.DIP 1 { code }is equivalent to the vanillaDIP { code }andDIP 0 { code }is equivalent to executingcode. Assumingcode :: 'C -> 'D, one has
DIP n :: 'a{1} : ... : 'a{n} : 'C -> 'a{1} : ... : 'a{n} : 'D
DROP ndrops thentop elements of the stack in one go. As can be expected,DROP 0is a no-op. One has:
DROP n :: 'a{1} : ... : 'a{n} : 'C -> 'C
While these instructions can be implemented with existing opcodes, native support allows their gas cost to be much lower. More CPU is typically consummed passing control between two opcodes than is consummed executing simple stack manipulation operations.
Partial application
Another instruction making its way in Michelson is APPLY which
allows performing the partial application of an argument to a lambda.
To be more precise, APPLY performs one step of currying followed
by a partial application in one go. The type of APPLY is the following:
APPLY :: 'a : lambda (pair 'a 'b) 'c : 'S -> lambda 'b 'c : 'S
and its semantics is as follows:
APPLY / x : code : S => { PUSH 'a x ; PAIR ; code } : S
This is a functional programming idiom that was sorely missed by some Michelson practitioners. It should help as well for code generation from higher-level languages, such as SmartPy or LIGO.
Chain Id
In the third stage of the voting procedure, a test chain is forked to let stakeholders try the new proposed protocol. We presented this test chain when the Athens proposal reached the third stage.
A transaction that is run in the test chain cannot be replayed on the main chain by an attacker thanks to the chain identifier (chain id for short): each chain uses a different identifier that is signed in each transaction.
Until now, smart contracts had no way to access the chain id of the chain they run onto and in particular they had to behave identically on the test chain and on the main chain.
In our proposed amendment, a new chain_id type is added to represent
Tezos chain identifiers. The new CHAIN_ID instruction can be used to
produce a value of this type, the current chain identifier.
Comparable types closed under products
In Michelson, collections such as sets, maps and big_maps
are indexed by elements which must be endowed with the structure
of a total order. A slang inherited from OCaml calls these types
“comparable”. Up to now, only finitely many types are comparable:
string, int, key_hash, etc
(look here
and look for “comparable types” for a full list).
Alas, this prevents using structured data to index maps
(especially for big_map). A possible hack to circumvent this limitation
is to first serialise the keys to bytes using PACK and then use
the serialised key. This is both costly and dangerous, as it forgets
typing information.
The new amendment partially lifts this restriction and allows us to use
finite products of comparable types as keys in types set and map.
Concretely, we implicitly endow finite products with the lexicographical
order constructed on that of the underlying base types.
Deprecations/semantics alterations
Overview of the deprecations
The main deprecations are the following:
STEPS_TO_QUOTAis deprecated, as its semantics was dependent on a gas cost model subject to constant evolution and as it made evaluation of Michelson smart contracts non-monotonic in the quantity of gas provided.CREATE_ACCOUNTdisappears.CREATE_CONTRACTchanges type. In our proposal, its type becomes:
CREATE_CONTRACT :: option key_hash : mutez : 'g : 'S -> operation : address : 'S
This reflects the disappearance of the manager, spendable and delegatable fields.
- NOW has altered semantics: it returns the timestamp of the previous block plus 60 seconds.
This partially mitigates selfish behaviour where a baker would selfishly arbitrate the timestamp
of the current block.
What happens to existing contracts?
At stitching time (if switching from Athens to this new proposal),
some contracts may be augmented with extra entrypoints to render them compatible with the new protocol.
The details of this process are partially described on
Cryptium Labs’ blog
and will be detailed with the full changelog of the protocol.
Keeping it short (and incomplete), the fate of a pre-existing contract will depend on its nature.
- Scriptless contracts will be upgraded (for free!) to smart contracts replicating
the functionality of the deprecated
manager,spendableanddelegatablefields using the new entrypoint mechanism. The precise code used will depend on the state of these fields at stitiching time (so that non spendable contracts do not become spendable, for instance). - Spendable smart contracts will we augmented with an extra
%doentrypoint that will allow the tz1 who was its manager in Athens to execute arbitrary code, in particular to set the delegate or spend the funds. We will provide a detailed explanation of how to migrate existing software that uses scriptless KT1s, and **the command line client will implement backwards compatibility for commandstransferandset delegate. The current parameter type of these contracts will be assigned to the default entrypoint. - Delegatable smart contract will be augmented with
set_delegateandremove_delegateentrypoint in a similar fashion. - A corner case is the one of contracts that are deployed before the
migration, and have a
%defaultentrypoint. Without a special treatment, these contracts would change type after the migration to be of the type of their default entrypoint. For this, they are augmented with a%rootentrypoint at the root, and a special treatment is done for them, so that their%defaultand%rootentrypoints can be considered interchangeable where needed.
We are doing the final tests to ensure that all contracts deployed as of today will be fully operational after the migration.
The only case of possible breakage is with CREATE_CONTRACT. Indeed,
this instruction may succeed to produce a transaction, that in turn
may fail if the code contains deprecated instructions. The rationale
for that is trivial: all code already introduced in the blockchain can
use deprecated instructions, but no new code can be introduced that
includes deprecated instructions. This is currently a non-issue, as no
contract uses this instruction in the chain (there are few use cases
for it).
How should I prepare as a contract author?
For contract writers who are currently developping smart contracts that are to be deployed both before of after the migration, we recommend the following practices.
First, in the unlikely scenario where you were using some of the instructions being deprecated, please do not use them. If the migration happens, you will have to rewrite your contract if you want to redeploy it later.
Regarding entrypoint annotations, either make sure they are well formed, or do not use them at all.
Related to the previous points: try deploying your smart contract in a sandbox with the new protocol.
Finally, avoid using CREATE_CONTRACT if possible. This instruction
is a tricky one, tied with the semantics of the chain, and it may be
upgraded again in a future update. A simple pattern to originate
contracts from a contract is to wrap the CREATE_CONTRACT in a
lambda, and have the contract accept an authenticated (lambda unit
(list operation)) exactly as the manager.tz contract does.
Gas cost overhaul
Foreword
Gas costs are subject to change, as we continuously refine our understanding
of the resource consumption of the protocol. Never rely on hard-coded gas
constants and --dry-run your transactions. The following are important points
for this particular proposal.
- we do not change per-block and per-operation gas limits (more on this below);
- the update to Michelson gas costs does not impact the gas cost for vanilla
transactions (
tz1totz1). Other parts of this proposal could however alter these costs slightly. We won’t be concerned with this here.
Overview of the gas update
Gas cost is a proxy for resource consumption, especially time consumption. If you read this fine analysis of Emmy+, you know that ensuring timely termination of computations is paramount to the health of the network.
To summarize, overestimating gas costs prevents developers from writing more interesting contracts, while underestimating these costs leads to possible attacks. It is important to get this right.
During the last six month, we spent a fair amount of energy building a comprehensive infrastructure for benchmarking parts of the protocol and fitting statistical models of their resource consumption to data generated by benchmarking. We particularly focused on the Michelson interpreter, as having expressive smart contracts is a key element in the value proposition of Tezos.
The outcome of our work is new gas costs for Michelson instructions. Before we get to
the details, the following should be noted:
- our new proposal does not change per-block and per-operation gas limits
(more on this below);
- the update to Michelson gas costs does not impact the gas cost for vanilla
transactions (tz1 to tz1). Other parts of the amendment could however
alter these costs slightly. We won’t be concerned with this here.
Methodology
The goal is to obtain a predictive model of the execution time of smart contracts as a function of the size of their initial data. Once such a model is obtained, it can be mapped to the gas cost model which is part of the protocol and which bills every executed instruction.
We opted for linear cost models, where the predicted execution time of each instruction is decomposed into a fixed cost and an operand-dependent cost. Here, “linear” means that the model is going to be a linear combination of fixed, typically nonlinear basis functions. All the difficulty lies in guessing these nonlinearities by staring at the code and at the empirical data.
As an example, let’s take the ADD instruction on integers. Under the
hood, this instruction is dispatched to an efficient arbitrary-precision
arithmetic library. Generating a bunch of random stacks of integers up to 100 kb
and measuring execution time of the interpreter on ADD, we get the following
bunch of points:
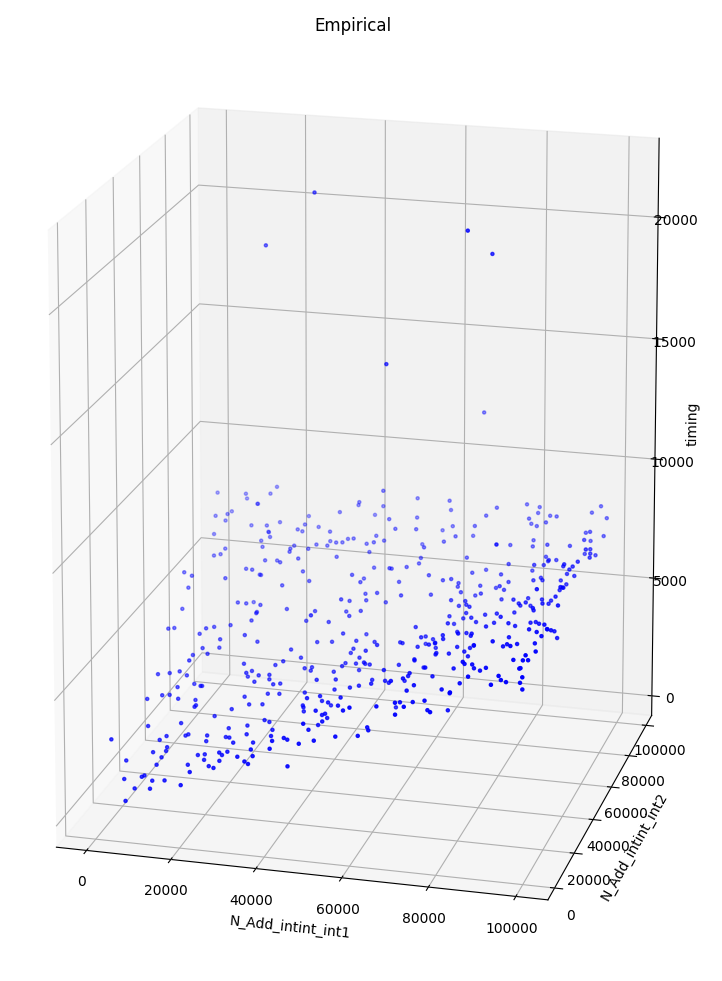 Here, the \(x\) and \(y\) axes correspond to the sizes, in bytes, of the pair of integers being
added while the \(z\) axis measures execution time in nanoseconds. We observe
that the data is mostly lying on two hyperplanes symmetric wrt the \(x=y\) plane.
We guess that the execution time of this instruction on integers \(x, y\) of sizes
\(|x|, |y|\) is of the form:
Here, the \(x\) and \(y\) axes correspond to the sizes, in bytes, of the pair of integers being
added while the \(z\) axis measures execution time in nanoseconds. We observe
that the data is mostly lying on two hyperplanes symmetric wrt the \(x=y\) plane.
We guess that the execution time of this instruction on integers \(x, y\) of sizes
\(|x|, |y|\) is of the form:
Here, \(\theta_0, \theta_1\) are unknown parameters (measured in seconds)
that have to be fitted to the empirical data. The conclusion of this
process is either the that the model is wrong or a set of parameters which
make the model effectively predictive. In this favourable example, our
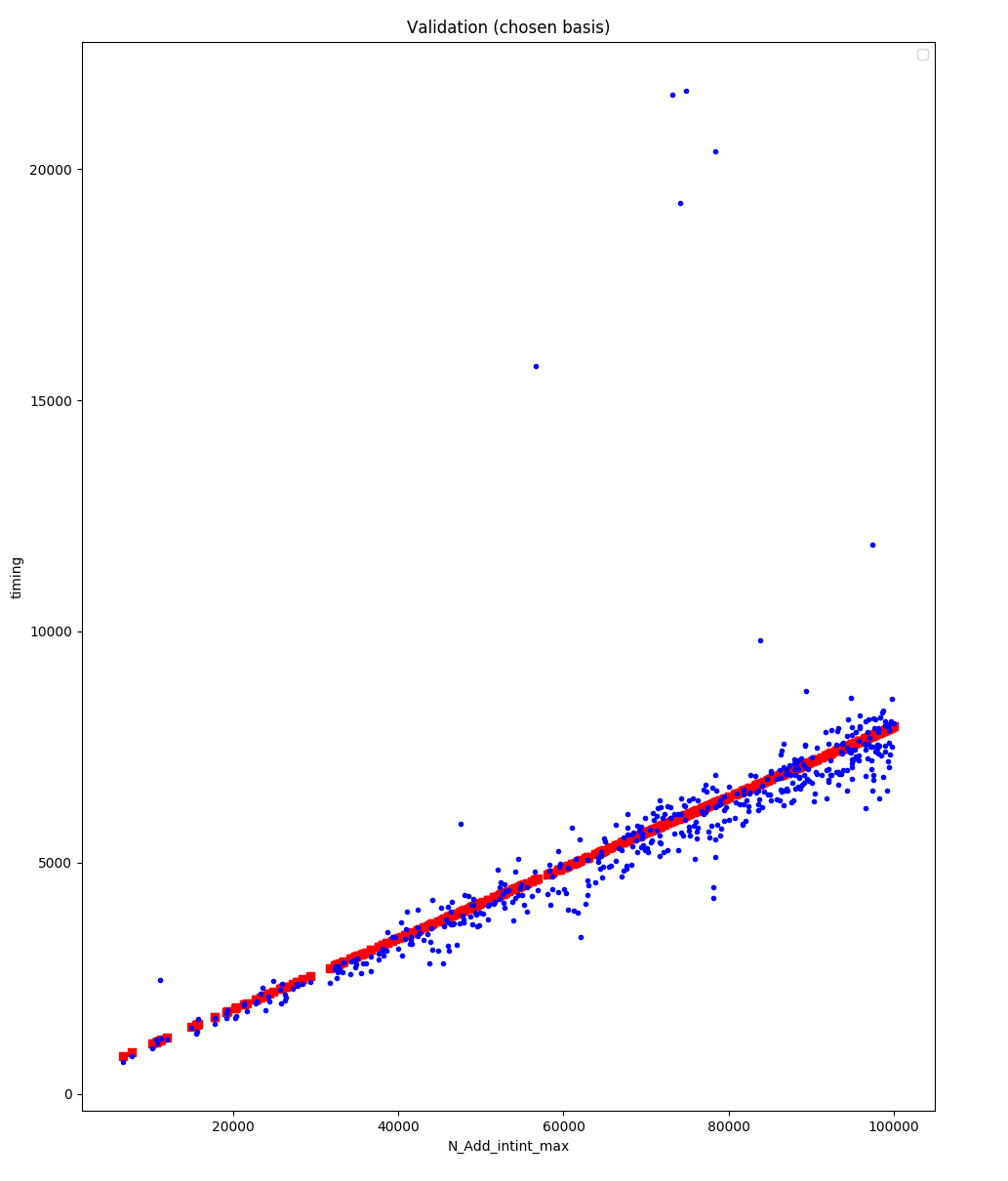
guess is particularly good: when projecting the empirical data into
the basis spanned by our chosen nonlinearity (the \(max\) function), we
see that the data is indeed living close to a linear subspace, easily
fitted (in red):
The last step is to convert this model into a cost function labelled in gas, implemented in the protocol. Our framework allows to perform all these tasks mostly automatically (except for guessing a good linear model). This is important, as there are close to one hundred instructions, not all as easy to fit as addition. Automatisation lessens the risk of mistakes being made in this rather tedious process.
Outcome
As a result, we now have a reasonably tight cost model for 90% of Michelson instructions. The missing ones are those involved with serialisation and typechecking, which require deeper work.
Let’s have a look at the gas costs of some smart contracts with &
without the new features. These are tests you can easily replicate at home.
We’ll be comparing gas costs in zeronet, which runs
a preliminary version of the new protocol, to gas costs in a mainnet
sandbox. We’ll call these versions respectively 005 and 004.
We’ll start with a simple loop:
parameter int ;
storage unit ;
code { UNPAIR ;
DIP { DROP } ;
DUP ;
NEQ ;
LOOP { PUSH int 1 ; SWAP ; SUB ; DUP ; NEQ } ;
DROP ;
PUSH unit Unit ;
NIL operation ;
PAIR
}
This contract expects an integer specifying a number of iterations.
Originating this contract costs roughly the same in 004 and 005:
13035 vs 12756. Each origination or contract call has a minimal fixed cost
of 10000 gas, for issuing the operation. In the case of an origination,
one also pays for typechecking and storage of the script.
Calling this contract on eg arguments 5, 5000 and 13000 in 004 costs
respectively 13197, 283530 and 769957 gas units. One will be
hard-pressed to go further: the per-operation gas limit is fixed to
800000 gas units both in 004 and 005.
Running the contract with the same inputs in 005 yields much
lower costs: respectively 12878, 31687 and 61812 gas units.
In fact, one can push the iteration number up to roughly
200000, for which the gas cost is equal to 765984, close to the
gas limit. We observe that gas costs for the involved instructions
significantly decreases in 005. Control flow and arithmetic should
be way cheaper that in 004.
Another interesting example is that of token standards such as the one announced here. A prototype implementation of this token standard is available here.
Looking at the large quantity of stack manipulation and control-flow related
instructions, we should have reason to expect significant savings in terms of
gas consumption for these important contracts. Origination costs are
146289 units of gas in 004 and 145974 in 005, a slight improvement.
More importantly, calling the two basic entrypoints %mint and %burn
have similar costs—even slightly higher in the case of %burn!
This is a consequence of the fact that runtime cost of control-flow and arithmetic instructions is negligible compared to the costs of serialisation, typechecking and storage incurred by manipulating big maps.
What’s next for gas
We now have a robust cost model for a large subset of instructions, and an infrastructure to continue updating the gas costs as the protocol evolves. As said in the beginning, defining a proper cost model for serialisation, typechecking and storage is going to be one of the top priorities of the gas team for the rest of this year. We’ve more plans in mind to rethink the architecture of ressource accounting in Tezos and make this part of the protocol more transparent for users and bakers alike.
Conclusion
This protocol update contains a wide array of new features which we think greatly improve the usability of Michelson both as a programming language for power users and as a target for emerging higher-level languages.
It is quite exciting to have the opportunity to continuously refine the protocol thanks to Tezos’ self-amending nature, and we hope that the community will be as enthusiastic when discussing and debating the content of this proposal.