TL;DR The latest Octez major release introduced a long-awaited feature: context pruning for rolling and full nodes’ storage — aka the garbage collection of the context storage. Context pruning significantly reduces disk usage of Octez nodes, lowering the barrier of entry, and improving the quality of life of node operators and bakers.
Where does all this data come from?
A desirable property of any blockchain is that the chain grows. Most blockchains share the notion of a “genesis block” — a Big Bang event where the first block was produced, and information is added continuously and (hopefully) forever: transactions, smart contract calls, NFT mints, etc. Ultimately, this ever-growing amount of data has to be stored by node operators.
In Tezos parlance, we speak of context when referring to the ledger state. For each blockchain level, the context reflects the account balances, the code and storage of smart contracts and other global data pertinent to the business logic of the Tezos economic protocol: information about stake and consensus rights, tickets, global constants, and more, that are updated by the block operations of a given level.
Moreover, the context storage in the Octez node is versioned: you
can think of the context store as a key-value store mapping each
block level (or each block hash) to the full context at that level. Of
course, the real implementation is smarter (and more efficient). The
Octez node relies on the Irmin storage system,
developed and maintained by Tarides, which
compresses and optimizes this history. Irmin works in a similar way
that Git works, storing diffs
between different versions of the same entry rather than recording
each version of an entry in full1. Still, this takes some space.
Thus, starting from its origin block, almost 3 million blocks ago2 the size of the Tezos storage never stopped growing.
Why do we need to keep all this data around? There are two parts to the answer to this question. First, it is paramount enough participants do: For the sake of verifiability, we need to be able to replay — that is, to reproduce — the complete history of the Tezos blockchain from its genesis block to a desired point in time and see the resulting context is the expected one. This tasks entail being able to find the contents from any given block, at all times so we can apply them on top of the predecessor block’s context.
Then, storing the results of those computations (the context is computed and updated each time a node validates a new block) makes sense for efficiency purposes as well — compute once, read from disk later, as those values are immutable3. For instance, a baker should not need to replay the chain each time to find out, say, what were its delegators balances during the recent cycles in order to pay delegation rewards.
Do we all need to keep this data around? Indeed, not every node operator requires access to the complete history of the chain: a baker doesn’t need to know all the chain’s history to bake new blocks; and we rather rely on indexers and block explorers to query operation details from any given block in the past.
To cater these different needs, the Octez implementation provides different storage modes, known as history modes: rolling, full, and archive. Nodes running in archive history mode keep all data (and metadata) from all operations since genesis, while nodes running rolling or full history modes keep less information, and hence demand a leaner footprint. Indexers and block explorers rely on archive nodes, whereas bakers are recommended to rely on full nodes.
Even for users running the lighter rolling and full history modes, keeping multiple versions of the context imposes a significant disk space overhead.
Starting with Octez v15.0, we incorporate the first version of a long-awaited feature, dubbed context pruning4. This recurrent maintenance process drastically reduces the disk footprint of the context store for full and rolling nodes, and the overall free space required to operate an Octez Tezos node. Moreover, users should notice an overall improvement in node performance as well!
This feature is a result of our ongoing collaboration with Tarides. The bulk of the work entailed working under the hood in Irmin, to implement the necessary changes in the overall architecture so that the Octez node could profit from this new functionality.
Tarides has published a quite detailed, in-depth article about the technical aspects of context pruning, garbage collection, and the intricacies of its implementation within Irmin.
Today, we rather focus on a higher level description of this feature and how it fits in with the overall Octez architecture, and provide a report of our early experimentation on the impact of the new feature on our working Mainnet nodes.
What’s context pruning then?
As we mentioned earlier, there are three different history modes in Tezos. And here today we focus on two: rolling and full. These two history modes aim to keep only relatively recent chain data, and reduce the disk footprint of the node’s data directory. The full history mode stores the minimal data necessary to replay the chain from genesis, but doesn’t snapshot context information from older levels, like older balances or staking rights. The rolling mode is even more aggressive, as it keeps information from just a limited number of cycles — on Mainnet, the default is the last 6.
Still, the way in which irmin-pack (the Irmin back-end used by and
conceived for Tezos) was designed did not allow to fully reap the
rewards of running leaner history modes: it was not possible to
“delete” the information from dead, unreachable objects (the data from
blocks deemed to be too old to be kept in the
store),
and reclaim valuable free space without prohibitive performance trade-offs.
The new Irmin version addresses this limitation by re-structuring the design of the context store.
How does context pruning work? Context pruning is, in essence, an automated garbage collector (GC) mechanism. It executes periodically, and asynchronously, with regard to other Irmin tasks. The GC determines a window of data to be kept, and iterates over the data on disk to extract the information from blocks belonging to that window which needs to be preserved — those from reachable objects only. When all the reachable data is extracted, the storage will switch to that newly garbage collected data, and drop the former one, which contains unreachable objects.
As a result, once context pruning kicks in, the disk footprint from the context increases linearly in its true size instead of the age of the data directory, eliminating the need for manual maintenance operations on long-running Octez nodes. In addition, the reduced footprint entails a better performing Octez node, as read and write accesses become cheaper.
We refer to Tarides’ blog post for further details on how the process works. In the following section, we revisit the impact the new context storage has on Mainnet nodes.
Putting pruning in context
As excited as you are to test this new feature, we ran a limited experiment to assess the impact in our Mainnet nodes.
The experiment consisted in importing the same rolling Mainnet
snapshot on two similar machines:
- one running a vanilla Octez v15.0 node — that is, with context pruning enabled; and,
- one machine running a v15.0 Octez node with context pruning manually (and artificially) disabled — so, no pruning for you.
The purpose of the experiment was to simulate running both nodes under the same conditions and throughout a period of time (validating around 40 cycles in a row) where we could witness the effect of several calls to the context pruning mechanism.
Figure 1 below plots the disk footprint of context storage on both machines; the raw data snapshot can be explored interactively here.
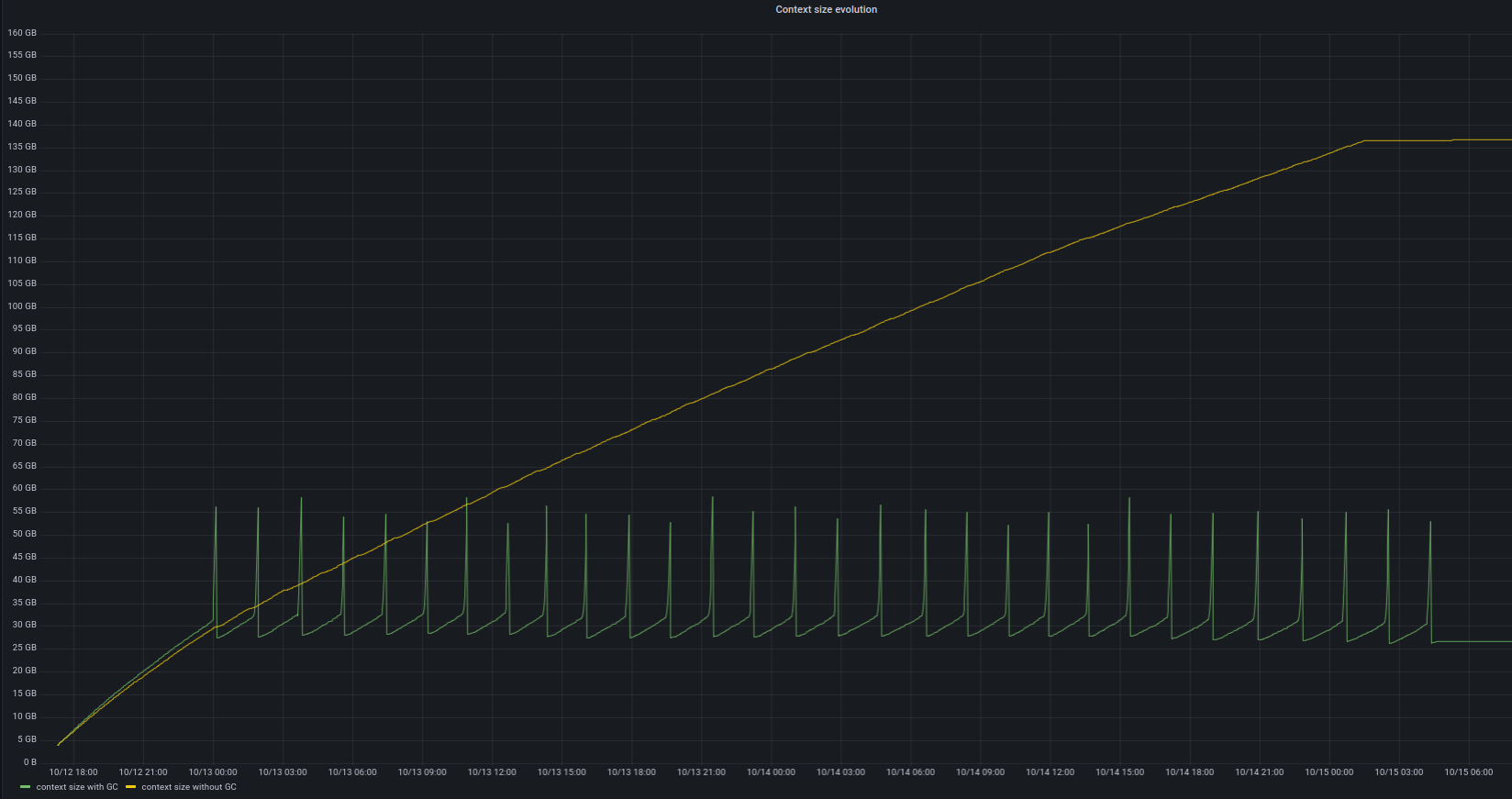
We see that the disk footprint from the stored context for the “artificially unpruned” node quickly rose up to ~140 GB. On the vanilla Octez v15.0 node with context pruning enabled, the size of the context storage on disk is significantly smaller: it oscillates between ~30GB and ~60 GB — the spikes are caused by the duplication needed before the context pruning calls, and they will be lowered in upcoming Octez releases. Still, that’s a 2x — 4x reduction in disk footprint!
How to profit from context pruning
To benefit from context pruning, there are a few simple steps to
follow. As the storage requires a particular format introduced in
Octez v13.0 (storage
version 0.0.8), it is mandatory to make sure that your node is
running with such a compatible storage format.
The easiest way to make sure of that is to import a fresh snapshot using an Octez v15.1 node. You will find detailed instructions on how to import snapshots in the online docs.
If the data directory was imported recently enough, that is by a node running Octez v13.0 or later, then you can skip the step to import the snapshot. However, the first context pruning operation for nodes that have been running on the same data directory for a long time can take a while, and use a significant amount of memory. To avoid this, it is also recommended to import a fresh snapshot.
As context pruning is enabled by default, there is nothing much to do. If you have configured your node as usual, you should be all set. If something is amiss though, a warning message like this will be printed while starting your node.
... : garbage collection is not fully enabled on this data directory:
context cannot be garbage collected. Please read the documentation or
import a snapshot to enable it.
That’s pretty much all you should care about. Context pruning being an internal maintenance procedure, we have not considered (yet) scrapping specific telemetry to monitor it — other than, of course, witnessing its effect by measuring the full size as in Figure 1 above5. This maintenance procedure is executed at each cycle dawn. Note that, if you have imported a fresh snapshot, context pruning will only occur after having validated blocks from 6 complete cycles, i.e. around 3 weeks6.
Looking ahead
While a significant part of our collective focus in 2022 has been on developing and deploying Tezos (vertical) scalability solutions — like transaction or smart rollups — that doesn’t mean we have forgotten about making the Tezos Layer 1 faster and more secure. Together with earlier improvements to the Octez node’s storage layer, context pruning makes the overall node leaner, demanding less resources, and improving overall quality of life for node operators and bakers. In addition to that, it also improves the performance: a lighter context implies faster read/writes.
Further upgrades to Irmin and context pruning. As Tarides’ blog post announces, this is a first deployment of the context pruning mechanism, and more improvements to Irmin are already in development for future Octez releases. These target:
- Avoiding duplication of the context before the actual pruning takes place (effectively keeping the footprint around 40GB).
- Improving the overall performance of the mechanism to be less resource intensive.
- Adding “a lower” layer to archive nodes, so that old data will be kept in it. The live data will remain in an lighter “upper layer”, allowing an overall performance increase.
Other changes in Octez v15.x In addition to the context pruning
feature described in this article, the latest Octez major release
includes other minor changes. It is also worth pointing out it was
recently superceeded by a new minor release, Octez
v15.1,
to correct a small-but-critical bug in the bootstrap
pipeline. We
invite you to take a careful look at the
Changelog before
upgrading your node. Another breaking change is a complete renaming
of all executables: tezos-client is now named octez-client,
tezos-baker-014-PtKathma becomes octez-baker-PtKathma, etc. This
was an overdue change, to reflect that the Octez implementation is one
of possibly many Tezos node implementations, as described when we
announced the Octez
name. In
a previous blog
post,
we have expanded on this rationale, and discussed the
backward-compatibility mitigation provided in the release.
Getting ready for Lima! Note that the Lima protocol will activate on Tezos Mainnet on block #2,981,889, which is currently expected at early hours of December 19th CET. Octez v15.1 will be the minimal compatible version required in order to participate in the consensus. As such, we recommend you take sufficient time to test this new Octez version to avoid surprises closer to the activation date.
-
This is, of course, a very simplified version of the story. Tezos uses a particular Irmin back-end,
irmin-pack, developed by Tarides and catering for our special needs. If you are interested in learning more about it — this blog post is a good entrypoint. ↩ -
Or a bit over 50 months or 4 years and something in human time. But, as Tezos reminds ourselves on each protocol upgrade activation… the natural unit of time in a blockchain is the block height or level. ↩
-
Oh dear! if they are not. ↩
-
Aka as garbage collection of the context storage. However, we prefer to rather use pruning here because, unlike the case of good old, memory management, garbage collection, the data in question is definitely not garbage. Even if the technique is indeed a garbage collection mechanism — as we discuss later on. ↩
-
If Figure 1 caught your attention and you want to know more on how to monitor your Octez Tezos node, we recommend you add this recent article to your reading list. ↩
-
For consensus reasons, the Octez node must keep the information from at least 5 cycles, as prescribed by the
PRESERVED_CYCLESprotocol constant. To ease bakers’ daily operations, the node keeps one additional cycle by default — that is, a total of 6 cycles. Until this 6-cycle window is reached, no context pruning will be performed. ↩